Awesome Stock Ai
- date:
22 oct 2019
from google.colab import drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
import numpy as np; import random; import matplotlib.pyplot as plt
import pandas_datareader.data as reader
SOS=0; EOS=1
class DataToIndex:
def __init__(self,rawData,numEmbed,method='ratio'):
if method=='raw': self.data=np.asarray(rawData)
elif method=='diff': self.data=np.asarray(rawData[1:])-np.asarray(rawData[:-1])
elif method=='ratio': self.data=np.asarray(rawData[1:])/np.asarray(rawData[:-1])
self.k1=(numEmbed-2)/2; self.b1=(2+numEmbed)/2
self.k2=(max(self.data)-min(self.data))/2
self.b2=(max(self.data)+min(self.data))/2
self.indices=((self.data-self.b2)/self.k2*self.k1+self.b1).astype(int)
def plot(self,components=[10,100,1000]):
fft=np.fft.fft(self.indices)
plt.figure(figsize=(8,4),dpi=100)
for c in components:
copy=np.copy(fft);copy[c:-c]=0
plt.plot(np.fft.ifft(copy),label="fft:{}".format(c))
plt.plot(self.indices,label="real");plt.legend();plt.show()
def toData(self,index):
return ((np.array(index)-self.b1)/self.k1*self.k2+self.b2)[:-1].tolist()
def sample(self,inputSeqLen,targetSeqLen,sampleRange):
data=self.indices[sampleRange[0]:sampleRange[1]]
while True:
inputBegin=random.choice(range(data.shape[0]))
inputEnd=inputBegin+inputSeqLen
if(inputEnd+targetSeqLen<data.shape[0]):
input=data[inputBegin:inputEnd].tolist()
input.append(EOS)
target=data[inputEnd:inputEnd+targetSeqLen].tolist()
target.append(EOS)
#print(data[inputBegin:inputBegin+inputSeqLen+targetSeqLen])
return input,target
rawData=reader.get_data_yahoo('AAPL','2010-10-10','2019-10-10')['Close']
dataToIndex=DataToIndex(rawData,256,'ratio')
dataToIndex.plot(); dataToIndex.sample(3,3,[0,-1])
dataToIndex.toData([18, 19, 20, 1])
/usr/local/lib/python3.6/dist-packages/numpy/core/numeric.py:538: ComplexWarning: Casting complex values to real discards the imaginary part
return array(a, dtype, copy=False, order=order)
[0.8898152303867198, 0.890651054511195, 0.8914868786356702]

image.webp

image.webp
import torch; import torch.nn as nn; from torch import optim
import torch.nn.functional as F
class Encoder(nn.Module):
def __init__(self,numEmbed,hiddenSize):
super(Encoder,self).__init__()
self.hiddenSize=hiddenSize
self.embedding=nn.Embedding(num_embeddings=numEmbed+1,
embedding_dim=hiddenSize)
self.gru=nn.GRU(input_size=hiddenSize,
hidden_size=hiddenSize)
def forward(self,input,hidden):
embedded=self.embedding(input).view([1,1,-1])
return self.gru(embedded,hidden) # output,hidden
def initHidden(self):
return torch.zeros([1,1,self.hiddenSize]).to(device)
class AttentionDecoder(nn.Module):
def __init__(self,numEmbed,hiddenSize,dropoutProb):
super(AttentionDecoder,self).__init__()
self.embedding=nn.Embedding(num_embeddings=numEmbed+1,
embedding_dim=hiddenSize)
self.attention=nn.Linear(hiddenSize*2,numEmbed)
self.attentionCombine=nn.Linear(hiddenSize*2,hiddenSize)
self.dropout=nn.Dropout(dropoutProb)
self.gru=nn.GRU(input_size=hiddenSize,
hidden_size=hiddenSize)
self.outLinear=nn.Linear(hiddenSize,numEmbed+1)
def forward(self,input,hidden,encoderOutputs):
embedded=self.embedding(input).view([1,1,-1])
embedded=self.dropout(embedded)
attentionWeights=F.softmax(self.attention(
torch.cat((embedded[0],hidden[0]),dim=1)
),dim=1)
attentionApplied=torch.bmm(attentionWeights.unsqueeze(0),
encoderOutputs.unsqueeze(0))
output=torch.cat((embedded[0],attentionApplied[0]),dim=1)
output=F.relu(self.attentionCombine(output).unsqueeze(0))
output,hidden=self.gru(output,hidden)
output=F.log_softmax(self.outLinear(output[0]),dim=1)
return output,hidden,attentionWeights
class Trainer:
def __init__(self,rawData,savePath,method,
numEmbed=256,hiddenSize=256,learnRate=0.01,
teachProb=0.5,dropoutProb=0.1):
self.savePath=savePath; self.teachProb=teachProb
self.numEmbed=numEmbed; self.hiddenSize=hiddenSize
self.dataToIndex=DataToIndex(rawData,numEmbed,method)
#self.dataToIndex.plot()
self.encoder=Encoder(numEmbed,hiddenSize).to(device)
self.decoder=AttentionDecoder(numEmbed,hiddenSize,dropoutProb).to(device)
self.encoderOptimizer=optim.SGD(self.encoder.parameters(),lr=learnRate)
self.decoderOptimizer=optim.SGD(self.decoder.parameters(),lr=learnRate)
self.criterion=nn.NLLLoss()
def train(self,nIters,inputSeqLen,targetSeqLen,saveEvery,sampleRange):
self.losses=[];lossTotal=0
for iter in range(nIters):
input,target=self.dataToIndex.sample(inputSeqLen,targetSeqLen,sampleRange)
inputTensor=torch.tensor(input,dtype=torch.long).view(-1, 1).to(device)
targetTensor=torch.tensor(target,dtype=torch.long).view(-1, 1).to(device)
teach=True if random.random()<self.teachProb else False
prediction,loss=self.trainOne(inputTensor,targetTensor,teach)
lossTotal+=loss
if iter%saveEvery==0 and iter>0:
self.losses.append(lossTotal); lossTotal=0
plt.title("\nProgress {:2.2%}".format(iter/nIters))
plt.plot(self.losses); plt.savefig(self.savePath+'_loss'+'.webp'); plt.show()
self.save()
def trainOne(self,input,target,teach,evaluate=False):
prediction=[]; loss=0
if not evaluate:
self.encoderOptimizer.zero_grad();self.decoderOptimizer.zero_grad();
enOutputs=torch.zeros([self.numEmbed,self.hiddenSize]).to(device)
enHidden=self.encoder.initHidden()
for i in range(input.size(0)):
enOutput,enHidden=self.encoder(input[i],enHidden)
enOutputs[i]=enOutput[0,0]
#===============================================
deInput=torch.tensor([[SOS]]).to(device)
deHidden=enHidden
for i in range(target.size(0)):
deOutput,deHidden,deAttentionWeights=self.decoder(
deInput,deHidden,enOutputs)
if not evaluate:
loss+=self.criterion(deOutput,target[i])
if teach: deInput=target[i] # target as input
else: # own prediction as input
topValue,topIndex=deOutput.topk(1)
deInput=topIndex.squeeze().detach() # detach from graph
prediction.append(deInput.item())
if deInput.item()==EOS: break
#===============================================
if evaluate: return prediction
loss.backward();self.encoderOptimizer.step();self.decoderOptimizer.step()
return prediction,loss.item()/target.size(0)
def evaluate(self,input):
with torch.no_grad():
target=np.zeros(self.numEmbed)
inputTensor=torch.tensor(input,dtype=torch.long).view(-1, 1).to(device)
targetTensor=torch.tensor(target,dtype=torch.long).view(-1, 1).to(device)
prediction=self.trainOne(inputTensor,targetTensor,teach=False,evaluate=True)
return prediction
def load(self,path):
try:
checkPoint=torch.load(path+'.pth')
self.encoder.load_state_dict(checkPoint['encoder']); self.encoder.eval()
self.decoder.load_state_dict(checkPoint['decoder']); self.decoder.eval()
self.encoderOptimizer.load_state_dict(checkPoint['encoderOptimizer'])
self.decoderOptimizer.load_state_dict(checkPoint['decoderOptimizer'])
print('Loaded!')
except:
print("Model Not Found: "+path+'.pth')
def save(self):
torch.save({
'encoder':self.encoder.state_dict(),
'decoder':self.decoder.state_dict(),
'encoderOptimizer':self.encoderOptimizer.state_dict(),
'decoderOptimizer':self.decoderOptimizer.state_dict(),
},self.savePath+'.pth'); print("Saved!")
import json
class BenchMarker:
def __init__(self,nIters,configs):
self.nIters=nIters; self.configs=configs
self.rawData=reader.get_data_yahoo('AAPL','2000-01-01','2019-10-19')['Close']
def run(self,action):
log=[]
for method in self.configs["method"]:
for inputSeqLen in self.configs["inputSeqLen"]:
for targetSeqLen in self.configs["targetSeqLen"]:
savePathDir='/content/drive/My Drive/Colab Notebooks/Machine Learning/'
fileName=method+'_'+str(inputSeqLen)+'_'+str(targetSeqLen)
savePath=savePathDir+fileName
trainer=Trainer(self.rawData,savePath,method)
trainer.load(savePath)
if action=='train':
trainer.train(self.nIters,inputSeqLen,targetSeqLen,saveEvery=100,sampleRange=[0,-365])
elif action=='predict':
input,target=trainer.dataToIndex.sample(inputSeqLen,targetSeqLen,sampleRange=[-365,-1])
prediction=trainer.evaluate(input)
target=trainer.dataToIndex.toData(target)
prediction=trainer.dataToIndex.toData(prediction)
logItem={
'fileName':fileName,
'method':method,'inputSeqLen':inputSeqLen,'targetSeqLen':targetSeqLen,
'input':input,'target':target,'prediction':prediction,
}
self.plot(logItem,savePath); log.append(logItem)
with open(savePathDir+'StockAiBenchMark.json', 'w', encoding='utf-8') as f:
json.dump(log, f, ensure_ascii=False, indent=4)
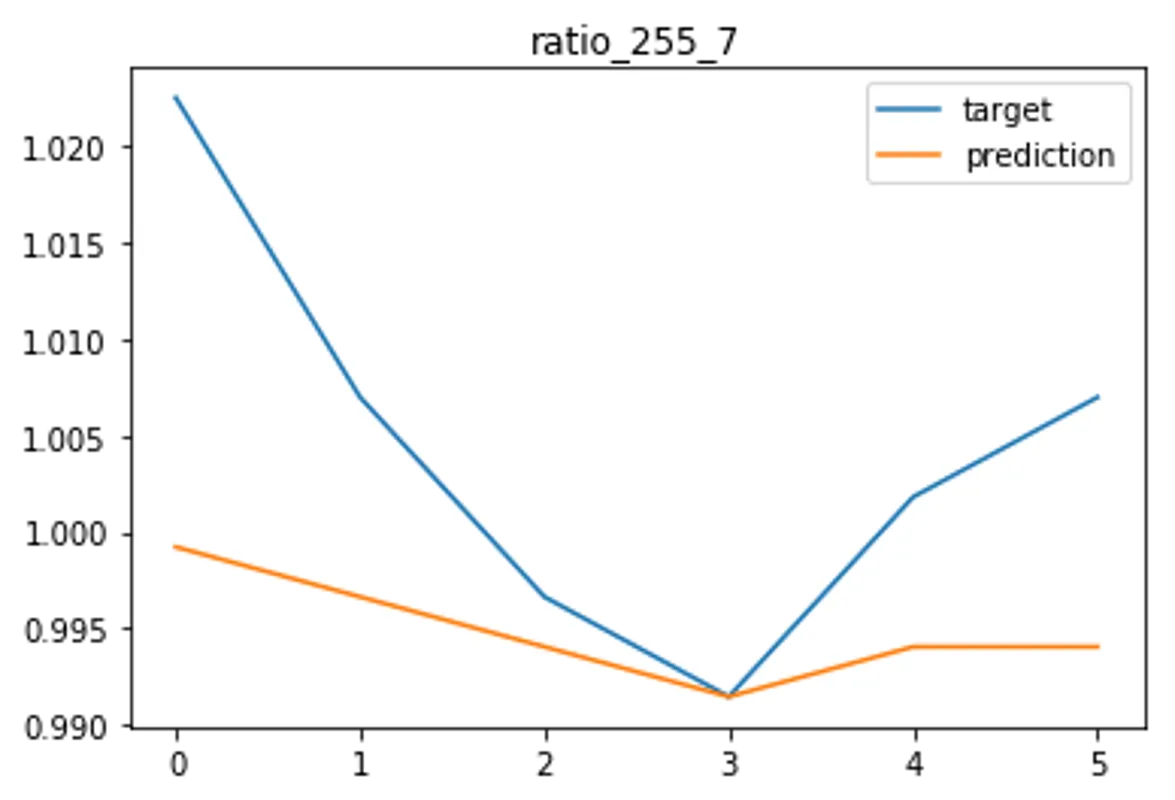
def plot(self,logItem,savePath):
plt.title(logItem['fileName'])
plt.plot(logItem['target'][:-1],label='target')
plt.plot(logItem['prediction'][:-1],label='prediction')
plt.savefig(savePath+'_predict'+'.webp'); plt.legend(); plt.show()
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
configs={
'method':['ratio'],
'inputSeqLen':[255],
'targetSeqLen':[7],
}
benchMarker=BenchMarker(10000,configs)
#benchMarker.run(action='train')
benchMarker.run(action='predict')
Loaded!